

标题
- 标题
- 内容

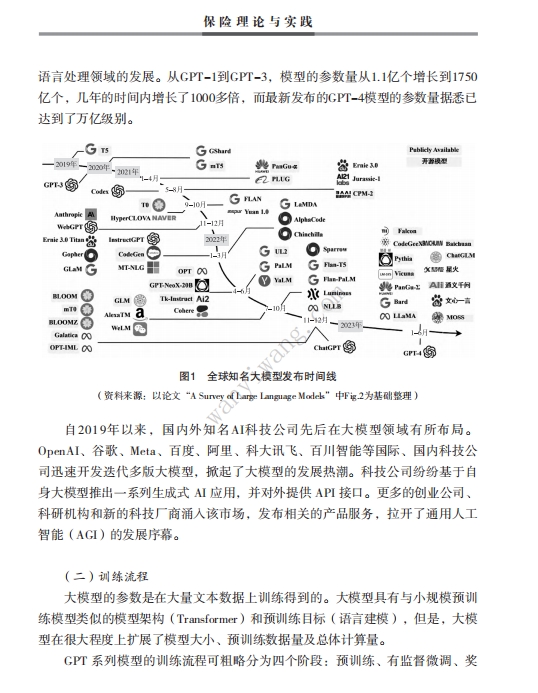
(一)大模型简介 大模型,全称大型语言模型(Large Language Model,LLM),指具有庞大参 数规模和较高复杂程度的机器学习模型,通常具有数十亿到数万亿的参数量。 大模型的设计和训练旨在提供更强大、更准确的模型性能,以处理更庞大、更 复杂的数据集或任务。大模型通常能够学习到更细微的模式和规律,具有更强 的表达能力和泛化能力。大模型需要大量的计算资源和存储空间,并且往往需 要进行分布式计算和特殊的硬件加速技术。 自2019年以来,国内外知名AI科技公司先后在大模型领域有所布局。 OpenAI、谷歌、Meta、百度、阿里、科大讯飞、百川智能等国际、国内科技公 司迅速开发迭代多版大模型,掀起了大模型的发展热潮。科技公司纷纷基于自 身大模型推出一系列生成式 AI 应用,并对外提供 API 接口。更多的创业公司、 科研机构和新的科技厂商涌入该市场,发布相关的产品服务,拉开了通用人工 智能(AGI)的发展序幕。
(二)训练流程 大模型的参数是在大量文本数据上训练得到的。大模型具有与小规模预训 练模型类似的模型架构(Transformer)和预训练目标(语言建模),但是,大模 型在很大程度上扩展了模型大小、预训练数据量及总体计算量。 GPT 系列模型的训练流程可粗略分为四个阶段:预训练、有监督微调、奖励建模、强化学习。(1)预训练(Pretraining):让模型通过自监督学习的方式,从大规模文本 数据中获得与具体任务无关的知识和语言能力,得到一个基础模型。 (2)有监督微调(Supervised Fine-Tune,SFT):根据标注的有监督微调 数据集对基础模型进行有监督的微调,得到SFT模型。 (3)奖励建模(Reward Modeling,RM):收集人工标注的对比数据,训练 奖励模型。 (4)强化学习(Reinforcement Learning,RL):基于奖励模型,使用近 端策略优化(Proximal Policy Optimization,PPO)算法进行强化学习,得到RL 模型。 (三)能力增强 大模型具有强大的内容生成能力和语言理解能力,同时,大模型有较为全 面的技术生态,可以通过工具、技巧进行能力扩展。 1. 推理能力:思维链(CoT) 思维链(CoT)是一种经过改进的prompt策略,可有效地提升大模型在复杂推理任务中的表现,包括常识推理、算数推理和符号推理。思维链不是简单地 使用“输入—输出”对来构建prompt,而是将产生最终输出的中间推理步骤加入 prompt,大幅激发了大模型解决复杂推理任务的能力。 2. 行动力:插件(Plugin) 行动力的增强主要体现在以插件(Plugin)技术为代表的工具利用。大模型 的本质是基于大规模文本语料训练的文本生成模型,大模型在数值计算、实时 信息检索等非文本生成型任务上表现不佳。针对该问题,业界使用外部工具来 弥补大模型能力的不足。例如,使用外部计算器进行精确的数学运算,使用搜 索引擎实现实时信息检索。ChatGPT是利用外部的插件体系来扩充大模型的能 力,为大模型“智慧的大脑”加上“灵巧的双手”,提升了大模型的知识面广 度、数据实时性及业务执行力。
全国统一客服热线 :400-000-1696 客服时间:8:30-22:30 杭州澄微网络科技有限公司版权所有 法律顾问:浙江君度律师事务所 刘玉军律师
万一网-保险资料下载门户网站 浙ICP备11003596号-4  浙公网安备 33040202000163号
浙公网安备 33040202000163号


